让不懂建站的用户快速建站,让会建站的提高建站效率!

发布日期:2025-12-19 13:46 点击次数:132
金磊 发自 凹非寺
李飞飞团队最新的空间智能模子Cambrian-S,初度被一个国产开源AI超过了。
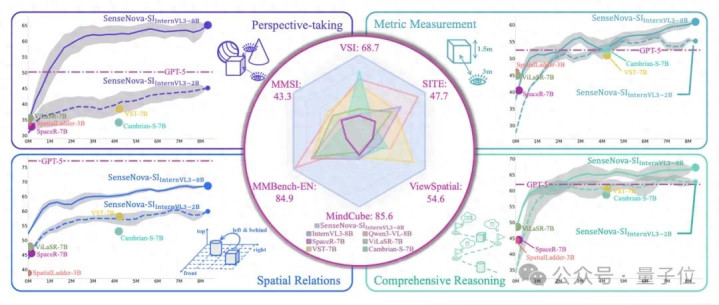
从这张展示空间感知智商的雷达图中,一个名为SenseNova-SI的模子,它在多个维度上的智商评分均已将Cambrian-S给包围。
况兼从具体的数据来看,岂论是开源或闭源,岂论是2B或8B大小,SenseNova-SI在各大空间智能基准测试中齐拿下了SOTA的收获:
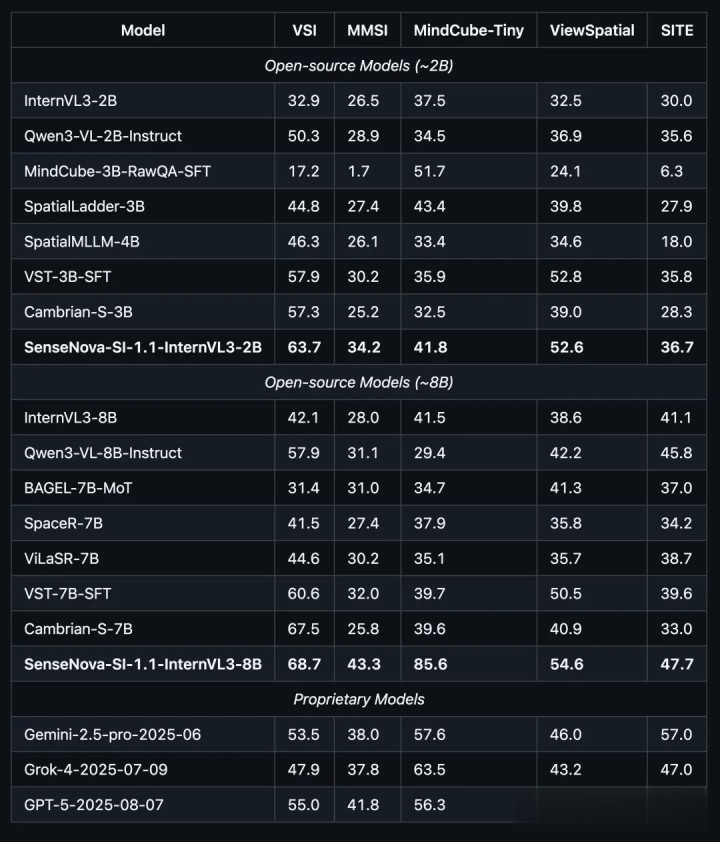
而这个SenseNova-SI背后的操刀者,恰是商汤科技。
在量子位与商汤科技衔接首创东谈主、首席科学家林达华深入调换进程中,他并莫得遮挡对这一进展的细则:
在空间智能这个赛谈上,基于永恒的视觉积贮,咱们依然走到了全国前哨。
但与此同期,林达华亦然当场话锋一排,默示他并不肯意把这个故事简便地讲成“赢了李飞飞”或者“赢了OpenAI”。
更深层的,林达华更像是在开释一种信号,一个对于AI本领范式正在发生剧烈轰动的信号——
单纯依赖参数限制的AI范式妥当靠近瓶颈。咱们站在了新的十字街头。
因为在Scaling Law的边缘效应驱动递减、许多东谈主还在内卷谎言语模子时,林达华和他的团队接收的却是一条很少有东谈主走的路:Back to research(归来实验室)。
具体而言,是从最底层驱动死磕原生多模态和空间智能,以此来完成一场从Words(话语)到Worlds(全国)的迁移。
而在林达华看来,在这场迁移中,中国科技公司依然抢到了一张船票。
咱们该归来实验室了
回望曩昔三年,从2022年11月ChatGPT横空出世,到GPT-4的震撼登场,AI行业阅历了一场狂飙式的强横助长。
那是一个把Scaling Law奉为圭臬的时间,只须算力满盈大、GPU满盈多、数据堆得满盈高,模子的智商似乎就能无尽增长。
但到了2024年下半年,风向变了。
东谈主们发现,固然榜单上的分数还在涨,从GPT-4到GPT-5.2,再到Gemini的多样升级版,分数的跃迁越来越快,但带给东谈主们的惊艳感却在边缘递减。
林达华片言只语地指出:
底本的旧旅途,也即是单纯依靠Scale的主流范式,固然把模子推到了一个很高的高度,但也妥当触遭逢了天花板。
分数擢升越来越快,但模子对物理全国的施展力、对复杂逻辑的泛化智商,并莫得完竣质的飞跃。
与此同期,OpenAI前首席科学家Ilya Sutskever的一声快什么“Back to Research”,在硅谷和群众AI圈里激发了不小的涟漪。

这与林达华的想考不约而同:
咱们之前的路是放胆出遗址,目前的路,必须是归来科研的实质。
为何会如斯?简便来说,因为纯话语模子的红利快吃收场。
目前的顶尖大模子,在数学、编程上依然接近奥赛金牌水平,但在清晰物理全国、处理三维空间关联上,可能连一个几岁的小一又友齐不如。
畴昔的AGI,毫不会只是一个陪你聊天的Chatbot,也不应只是活在文本的逻辑里。它必须是一个大略清晰物理全国、具有多感官智商的全国模子。
林达华强调说:
东谈主类的智能不单要话语。
东谈主类与全国的交互是多模态的——咱们用眼睛看,用耳朵听,用手去触摸。AI的畴昔,在于从读万卷书(话语模子)进化到行万里路(空间与全邦交互)。
在这个新旧友替的时候节点,商汤接收不再盲目奴隶谎言语模子的参数竞赛,而是掉转船头,向着原生多模态这快更难啃的主见进发。
目前的模子连手指齐数不清
目前的多模态大模子,大多齐是有局限性的。
对于这个不雅点,林达华给出了一个相配直不雅且略带幽默的案例。
哪怕是强如Grok或者GPT-4的早期版块,当你丢给它一张东谈主手的相片,问它有几根手指时,它频繁会自信地回复“5根”。
哪怕图片里的东谈主手因为角度或畸变理解出6根或4根,AI的谜底依旧是如斯。

再比如,给模子看一张简便的三维积木图,问它“从上往下看是什么姿色”,大多数模子齐会选错。
它们明明看到了图片,为什么还会瞎掰八谈呢?
因为它并莫得的确在看。
林达华打了一个极其活泼的譬如:
这就好比一个盲东谈主,在昏黑中闭眼学习了十年。他读了万卷书,大脑极其发达,逻辑想维严实。倏得有一天,你让他睁开眼看全国。
他的第一反馈是什么?是他会拚命地试图用他曩昔十年在册本里学到的语义想法,去硬套目前看到的东西。
在传统的多模态架构(拼接式架构)中,无为是一个视觉编码器(Vision Encoder)加上一个谎言语模子。
视觉编码器把图片翻译成话语模子能听懂的Token,然后扔给谎言语模子去推理。
在这个进程中,谎言语模子依然是阿谁“闭眼学习了十年”的大脑。它看到“手”这个图像Token,大脑里坐窝调出的先验学问是“手有5根手指”,会班师遮盖掉眼睛看到的真实像素细节。
林达华分析谈:
它不是确实清晰了三维空间关联,它只是在靠概率猜词。

这种拼接式的道路,固然能快速出恶果,但劣势是致命的:
视觉信号在插足大脑的那一刻,就被降维、被阉割了。多数的空间细节、三维结构、物理限定,在蜕变为话语Token的进程中流失殆尽。
这即是为什么目前的模子数学能拿金牌,却连手指齐数不清、连积木齐搭不解白的原因了。
要贬责这个问题,修修补补似乎依然是船到抱佛脚迟。必须从底层架构上进行一场透彻的矫正。
商汤原生多模态的解法
这场矫正的产物,即是商汤刚刚开源的NEO架构,以及基于此架构的SenseNova-SI模子。

在深入了解这个架构之前,咱们需要先清晰什么是原生多模态。
林达华的施展是这么的:
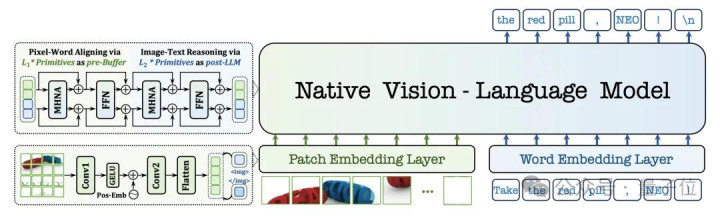
样式上不再是“视觉眼睛+话语大脑”的拼接。在NEO架构里,从模子最底层的Transformer Block驱动,每一个细胞齐能同期处理视觉和话语信号。
这听起来很概括,但在本领完竣上却极其硬核。
在NEO架构中,视觉Token和文本Token不再是“先后插足”或“翻译关联”,而是“一块插足模子的每一层。
商汤瞎想了专诚的羼杂提防力机制(Mixed Attention),让模子在进行每一次推理野心时,既能参考文本的高下文,又能及时“回头看”图像的原始特征。
为了让模子的确清晰空间,林达华团队还干了一件反直观的事——
他们不再只用忖度下一个词(Next Token Prediction)来实践模子,而是引入了跨视角忖度。
简便来说,即是给模子看一个物体的正面,让它去忖度这个物体侧面、后头长什么样。
林达华默示:
这就像教小孩子搭积木、看全国不异,你在脑海里构建三维模子的进程,即是空间智能出身的进程。
这种原生架构带来的效果是惊东谈主的——
数据效用擢升了10倍。
举例SenseNova-SI仅用了同类模子10%的实践数据,就达到了SOTA水平。况兼,它不再是靠死记硬背,而是的确清晰了三维空间关联。
正如咱们前文提到的对比评测中,SenseNova-SI不仅超过了李飞飞团队的Cambrian-S,更是在空间推理、幻觉扼制等要害目的上阐明更优。
林达华总结谈:
咱们但愿把一个闭眼决骤的盲东谈主,酿成了一个的确睁眼看全国的不雅察者。
落地,落地,还得看落地
本领再牛,要是不可酿成坐褥力,终究只是实验室里的玩物。
在量子位与林达华的调换进程中,他反复提到了一个词:工业红线。
咱们里面有一个圭表:任何本领,要是它的使用本钱高于它创造的价值,那即是没过工业红线。
这是因为大模子行业目前最大的痛点,除了不够智慧,即是太贵、太慢。
绝顶是在视频生成范畴,固然Sora惊艳了全国,但生成几秒钟视频需要破钞巨大的算力,推理时候动辄几分钟以致几小时。
这种本钱和蔓延,根底无法撑持大限制的交易应用。
“只须当推理本钱以每年1-2个数目级的速率下落时,AI能力从Demo级的炫技,酿成石油级的工业坐褥力。”
为了跨过这条红线,商汤在落地应用高下足了功夫。林达华以商汤最新及时语音驱动数字东谈主居品SekoTalk为例,展示了什么叫算法和系统协同的极致优化。
目前的视频生成主流模子齐是基于扩散模子,生成一张图每每需要迭代几十步以致上百步。
但这个进程的要害就不可减少吗?谜底是辩说的。
林达华团队诓骗一种名为算法蒸馏的本领,硬生生将扩散模子的推理步数,从100步压缩到了4步。
这不是简便的偷工减料,而是基于对模子踱步的潜入清晰。林达华施展说:
模子在从白噪声酿成图像的进程中,不同阶段处理的数据踱步是总共不同的。以前是用吞并套参数跑100遍,目前是分阶段用不同参数跑4遍,让专科的参数干专科的事。
如斯布置之下,效果依旧是惊东谈主:64倍的速率擢升。
这就意味着在不久的将来,你只需要一张消费级的显卡(比如RTX 4090以致更低),就能及时生成高质地的数字东谈主视频。

△SekoTalk生成的视频
聊至此处,林达华也阐明出了首肯之情:
以前生成20秒视频要跑一小时,目前咱们能作念到及时生成。这不仅是效用的擢升,更是交易样式的质变。
这班师买通了AI在直播、短视频制作等范畴的限制化落地旅途。
从SenseNova-SI的底层架构革命,到SekoTalk的极致落地优化,商汤正在践行林达华所说的双轮驱动:
一手捏Back to Research的原始革命,一手捏击穿工业红线的落地价值。
One More Thing
在对话的终末,林达华也为当下想要投身AI大波浪中的年青东谈主给以了一些珍爱的提议:
不要只盯着谎言语模子来卷,这个赛谈确实太拥堵了。
林达华敦朴地默示,年青一代的计划者和创业者,应该把视线大开。
具身智能、AI for Science、工业制造、生命科学……这些齐吵嘴常好的范畴。
智能不单要话语,AI的畴昔在于从读万卷书进化到行万里路。
林达华终末说谈,在这场从Words to Worlds的繁密迁移中,中国领有全全国最丰富的场景、最完好意思的工业体系。这片泥土,天生合适耕种那些能与物理全国深度交互的AI。
在这个赛谈上,中国科技公司依然抢到了一张船票;而畴昔的头等舱,属于那些勇于归来实验室、勇于勇闯无东谈主区的年青东谈主。
SenseNova-SI地址:https://github.com/OpenSenseNova/SenseNova-SI
NEO地址:https://github.com/EvolvingLMMs-Lab/NEO
— 完 —
量子位 QbitAI · 头条号
体恤咱们,第一时候获知前沿科技动态